The current state of enterprise AI is strange. Companies are spending piles of money in a rush to integrate AI into their business without a clear understanding of the problem they’re trying to solve. At first it seems easy. Plug in some API calls and you’re off to the races. Even simple no-code plugins for spreadsheets and presentations are instant productivity boosters.
But for analytical work where you need to combine deterministic accuracy with probabilistic analytical reasoning—for enterprises with growing needs, expansive data sets, and domain-specific lexicons—the off-the-shelf functionality and context windows hit a wall quickly.
That’s where the initial euphoria over early gains starts to turn into disillusionment over the apparent limitations. Hallucinations seep their way into results, making it less practical for widespread use. New users are asking why AI can’t access data outside its silo. New use cases within the organization are expanding, but how do you know the data inputs are ready for analysis by a semantic engine?
Suddenly there’s more complexity than optimizing a system prompt can handle.
This is where most enterprise AI projects fail. Not because the technology doesn’t work, but because the infrastructure around it was never built to last.

The 10,000 Pages Problem
LLMs are trained on human data. They give you the answer the collective human would respond with based on inputs. This makes them remarkably capable—and remarkably dependent on how you set them up.
Think of an LLM like a new employee. You wouldn’t throw 10,000 pages of historical documentation on someone’s desk and tell them to start a new project on day one. They need training, domain knowledge, and the right tools to be successful. They need context about what they’re working on, what resources they have access to, and how the organization actually operates.
You can’t skip this with an LLM and then get disappointed when it fails.
Most companies skip it anyway.
Why We Built Navigator
Navigator grew out of a specific problem. At Signalflare.ai, our job is creating end-to-end predictive analyses for non-technical users who aren’t looking for a pretty chart (okay, they might like a pretty chart too—but that’s insufficient)—they need a solid answer and guidance on what to do next.
That’s a complex series of steps. Disparate datasets need to be combined correctly—trillions of domain-specific records from multiple sources. Those records go through advanced machine learning processes that create predictive and prescriptive analytical results and run advanced simulations. The output is both traditional SaaS dashboards, reports, and analysis—and good old-fashioned human-to-human interpretation of what to do next.
The goal was to replace myself and as many of these steps as possible. Not as a generic system, but as a purpose-built engine for decision making.
Existing systems couldn’t do it. Home-grown systems were making it worse. Companies focus on their business—that’s what they should be doing. They shouldn’t have to solve the complexities that come with building enterprise AI systems from scratch.
So we built Navigator: a system capable of handling real work. Not demos. Not proofs of concept. Daily workloads that teams can depend on.
This meant solving for reliability first. A system that works most of the time is worse than no system at all in enterprise contexts—it erodes trust faster than having nothing.
The Core Problem: One Question, Many Answers
Here’s where most AI platforms get it wrong.
When you ask a typical AI agent a question, it doesn’t look up the answer. It generates one. It searches through possibilities using vector search—a probabilistic method that ranks potential responses by likelihood. This is how LLMs work. One question yields many potential answers, and the system picks the most likely one.
This approach is powerful for creative tasks. Writing, brainstorming, explaining complex concepts, synthesizing information across sources—probabilistic methods excel here. The LLM finds patterns and connections humans might miss.
But it’s a liability when you need the right answer, not a likely answer.
Your data pipeline can’t hallucinate. Your quarterly numbers need to be correct. Your ETL jobs need to run the same way every time. When an LLM guesses at these tasks, you get outputs that look plausible but fall apart under scrutiny.
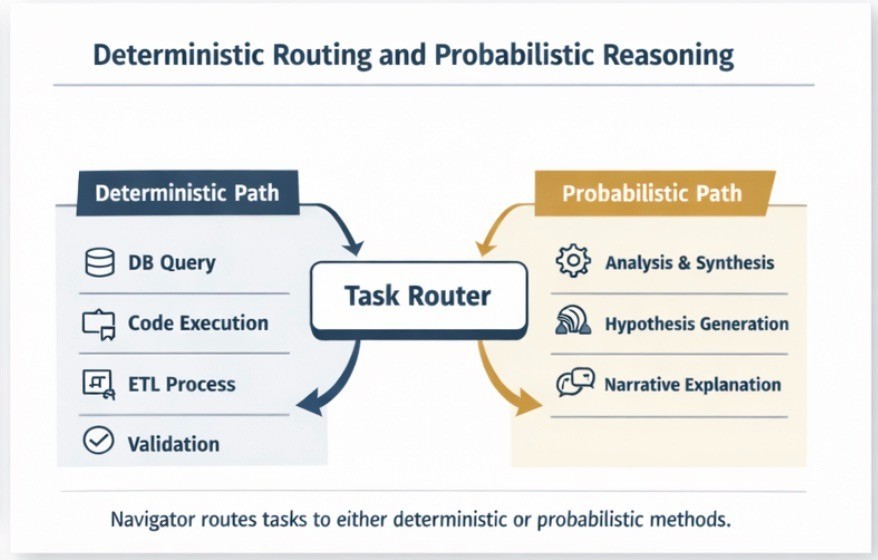
Deterministic Routing and Probabilistic Reasoning
Navigator takes a different approach.
For tasks that require certainty, Navigator uses deterministic routing. One question, one answer—the correct one. No probability distributions. No hallucination possible.
For tasks that benefit from creativity—analysis, synthesis, pattern recognition—Navigator preserves the full power of probabilistic LLM reasoning.
The platform connects to over 150 LLMs and foundational models, routing each task to the right tool based on what the work actually requires. Not every problem needs the same solution. A data transformation needs deterministic execution. An analysis of what that data means can benefit from LLM pattern recognition.
Navigator handles both, and can combine them in a single workflow.
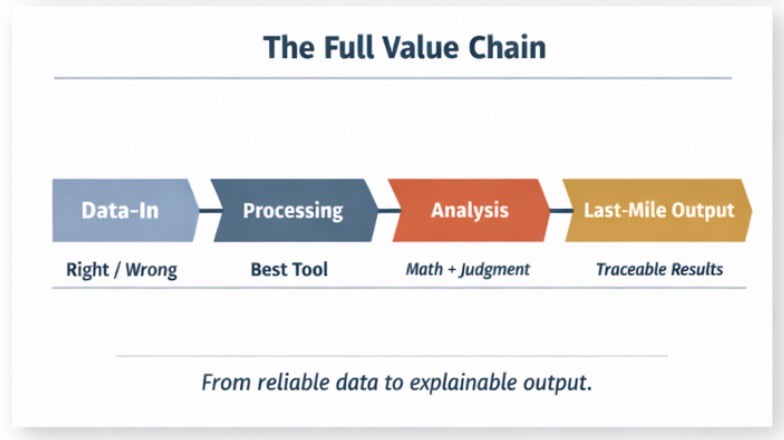
The Full Value Chain
This distinction matters because enterprise work isn’t one thing. It’s a chain.
Data-in needs to be reliable. Ingestion, transformation, storage—these are deterministic problems. The answer is either right or wrong. Navigator handles this with zero hallucination because it’s not asking an LLM to guess.
Processing requires the right tool for the job. Some tasks need specialized models. Some need traditional code execution. Some need both. Navigator routes to whatever the task requires.
Analysis is where Navigator’s dual capability matters most. There are two kinds of analyses: quantitative analyses that require a precise mathematical answer, and qualitative analyses where judgment and reasoning prevail. It’s combining these two where Navigator excels.
Signalflare is expert in advanced machine learning and has its own foundational and customer-specific models deeply integrated into our systems. This depth of analytics is not the same as telling an LLM to do a correlation analysis on the fly. It’s the difference between running correlation in Excel and producing an attribution model from a Bayesian neural net. They are not comparable—or should not be.
Navigator preserves the full power of probabilistic LLM reasoning for qualitative synthesis while routing quantitative work to the specialized models and deterministic processes that produce precise answers.
Last-mile output needs to be explainable. Non-technical stakeholders need to understand what the analysis means and why. Black boxes don’t work in enterprise contexts. Navigator produces outputs that can be traced, explained, and verified.
Most platforms treat every step the same way. Navigator doesn’t.
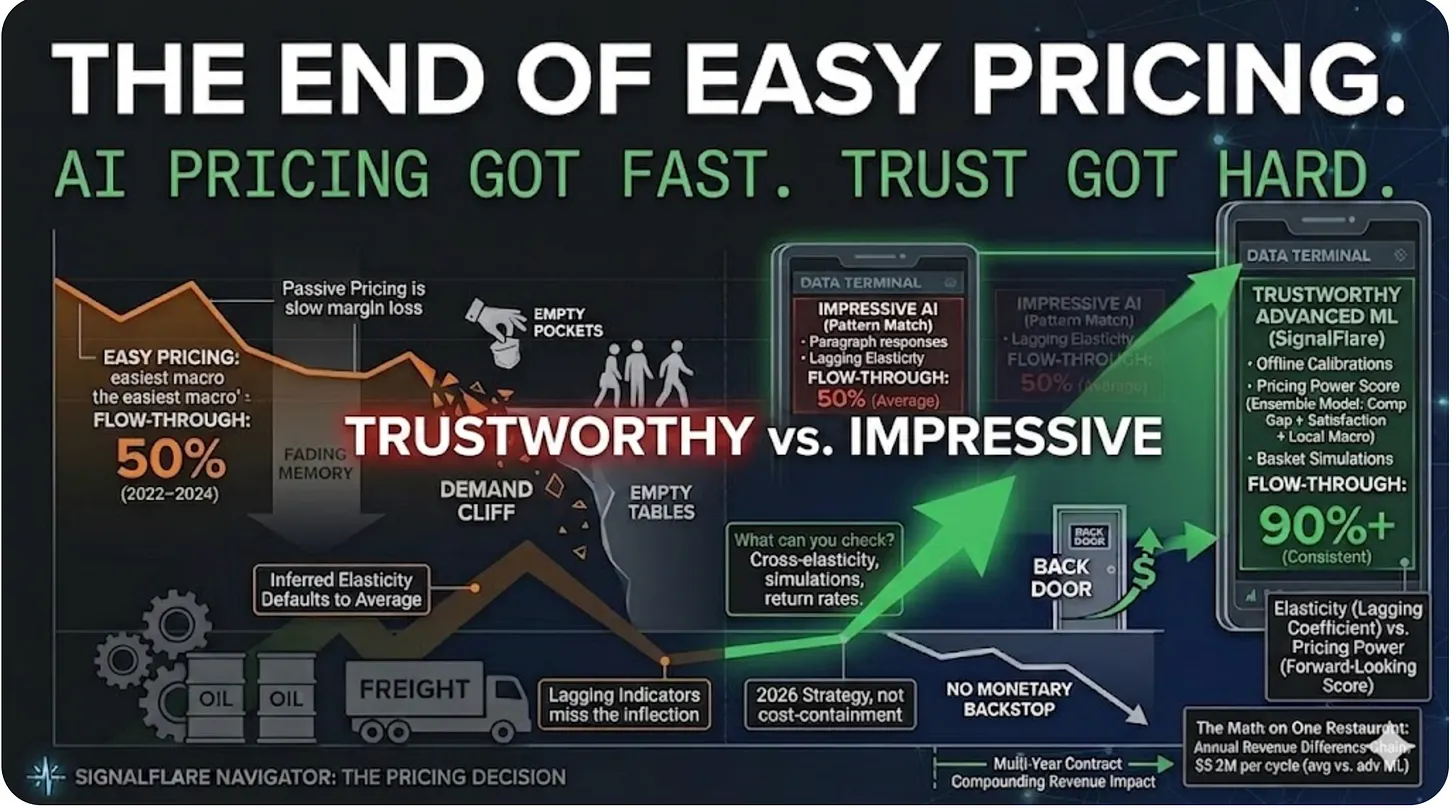
In practice, Navigator has shown 90% efficiency improvement in targeted analytical workflows. But as we roll it out into early release, the bigger potential is how quickly and efficiently it unearths insights into local market and store-menu dynamics that human analysts would have either missed or might never have had the time to analyze in such depth. And it’s not just the insights—it’s making real, tangible recommendations that pass muster with our seasoned professional analysts.
Finding the Right Level of Abstraction
Building this required solving an abstraction problem.
Too many narrow, specific tools and you blow up the context. The agent has no idea which tool it needs for any given task. It’s guessing—which defeats the purpose of deterministic routing.
Too much abstraction and you’re confined to set boundaries. The system can’t adapt when you need it to do something the original designers didn’t anticipate.
The approach we took: start with what a human in a business actually has. A computer. A file system. A database. Access to the platforms they work in. This gives the system nearly unlimited capability to create anything a developer could create with code.
Then segment down. Define the specific actions and resources needed for each task in a controlled environment. The full toolset remains available, but each workflow uses only what it needs.
This is how you get flexibility without chaos. The infrastructure supports both modes—deterministic execution when running code or querying data, probabilistic reasoning when synthesizing or explaining.
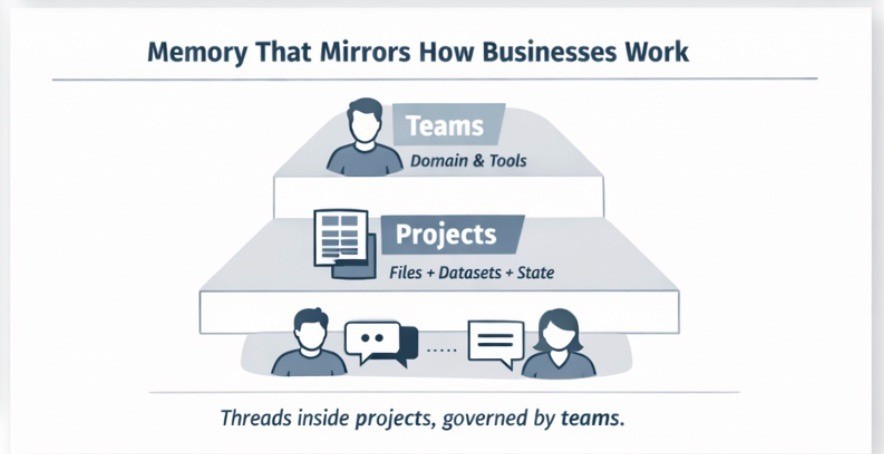
Memory That Mirrors How Businesses Work
LLMs don’t remember anything. They’re stateless APIs—you send inputs, you receive outputs. What most platforms call “memory” is just conversation history fed back into the context window.
This falls apart fast. Once you integrate tool calls, external datasets, and files, simple conversation history costs a fortune and delivers poor results. You’re feeding the LLM everything and hoping it figures out what matters.
Navigator uses a multi-tiered memory structure that mirrors how businesses are actually organized.
Threads handle agent interactions within a project. Users can interact with the agent, and the agent can semantically reference messages across those conversations as needed.
Projects cluster threads together with attached files and datasets. The agent has context on what it’s working on, its current state, whether it’s on track, and what external resources it can access.
Teams define domains—what users are working on, their specialization, the toolsets and knowledge and behavior appropriate for that context. An agent can behave very differently from one team to the next, highly refined to how each team works, while sharing the same core infrastructure.
This structure enables precision over volume. We can carefully craft what actually gets fed to the LLM, monitor exactly where it’s struggling—whether that’s parsing a file or making a tool call—and run targeted tests to improve that specific piece of the pipeline.
Technical Decisions That Support Durability
For non-technical readers: this section matters to you too. The framework choices below directly affect whether the system can scale reliably across your enterprise.
The codebase has one hard requirement: strong type safety. TypeScript throughout, minimal Python outside of machine learning code.
This isn’t language snobbery—no shame to Python programmers for the great things Python can achieve. But developers will understand that the framework we’ve chosen is important for enterprise scalability. Large codebases without strict typing become maintenance nightmares. If you’re building infrastructure meant to last, you need to catch errors at compile time, not in production.
We built on a TypeScript agent framework focused on primitives rather than abstractions. Most frameworks abstract everything and confine you to set boundaries. That helps people get started, but we needed a system that could adapt to anything we needed to implement.
Because the framework focuses on primitives, we can implement custom modules that satisfy those interfaces and swap them out without major refactoring. The framework doesn’t dictate what we can build.
Each of these decisions was made for long-term maintainability, not speed-to-demo.
Early Release Infrastructure
The features now in early release are aimed at making the user experience enterprise-grade—teams of multiple users, multiple data sources, all running simultaneously.
Caching for tool calls reduces context significantly. Repetitive tool calls return immediately from cache. A custom prompt cache pretokenizes inputs and outputs to reduce token usage further.
Per-project sandboxes give each project a separate environment with full file system and database access. This lets agents run code in isolated compute—testing internal code, importing and executing pipelines, running simulation engines. Separate environment, separate compute, full capability.
DataAPI opens internal sources and partner access through a semantic layer. Initial setup provides full semantic references, with query caching to optimize for speed and cost.
Durable streams replace the request/response model with persistent streams per thread. The agent and users can append to the stream from any device—Slack, browser, sandbox. All views sync to the same chat state in real time. This enables background data processes and ETL pipelines to run as background tasks with real-time status updates.
Each of these solves a real operational problem. None of them are features for the sake of features.
The caching alone makes Navigator’s total cost of use better than using the LLMs or database tools directly—because it’s managing multiple levels of memory through the agents, consolidating and summarizing to optimize processing and token usage. The goal is to make the most advanced deterministic agentic AI available at the best total cost of ownership.
The Difference Between Demo and Deploy
Trendy solutions optimize for impressive demos. They show what’s possible when everything goes right.
Enduring solutions optimize for reliability. They’re built for what happens when things need to work every time.
The deterministic/probabilistic distinction is the technical core of that difference. Navigator doesn’t treat every problem like a creative writing exercise. It knows when to be certain and when to explore. When to use the calculator and when to brainstorm.
That’s how you build AI infrastructure that lasts. Not by chasing what’s trendy, but by solving the actual problem—reliably, repeatably, at enterprise scale.
Companies should be able to focus on their business. The AI infrastructure should just work.
That’s what Navigator is for.
Nathan Lockhart is the founding technical architect of Navigator. Mike Lukianoff writes about data-driven decision-making at The Signal Flare.
Share