Every organization using AI strategically is, whether they’ve named it or not, making a bet on how humans and machines should collaborate. Most are betting on the wrong thing.
They’re deploying AI to automate tasks, generate reports, and answer questions faster. That’s productivity. It’s useful. It’s not the same as improving decisions — and decisions are where the real leverage is. The choice of where to open a location, how to price a product, which markets to defend and which to exit, when to invest and when to hold. These are the moments that compound over time. Get them right consistently and the advantage is structural. Get them wrong consistently and no amount of operational efficiency closes the gap.
Decision Intelligence is the discipline of making that collaboration explicit. It’s a framework for applying data, models, and AI to the decisions that matter — not to automate them, but to make them faster, better-grounded, and increasingly informed by what came before. The goal is not to replace human judgment. It’s to give human judgment better inputs, better context, and a memory that doesn’t reset after every meeting.
AI makes this more possible now than it has ever been. It also makes the consequences of getting it wrong more severe. Bad data and poor process don’t disappear when you put AI on top of them. They accelerate. A model running on inconsistent inputs produces confident wrong answers at machine speed. An organization that automates its decision workflow before fixing its data foundation doesn’t make better decisions. It makes bad decisions faster, with more conviction, and at greater scale.
That distinction is where most AI implementations go sideways. And it starts with the architecture.
The Three Layers — and Where Things Break

Decision Intelligence has three layers. Data Unification — the work of getting your information clean, defined, and connected. Intelligence — the analytics, models, and reasoning that turn data into something usable. Implementation — the context, recommendations, and actions that follow, and the feedback that flows back to the beginning.
The middle layer has been functional for years. The analytics infrastructure exists. Machine learning models, when given well-structured inputs, produce accurate outputs. That’s not the problem.
The problem has always been the first mile and the last mile. And for the same underlying reason: both require domain knowledge that traditional tooling cannot encode at scale. Agentic AI just changed what’s possible in both places. But the change only applies to organizations that built the right foundation — and that stopped treating every decision as a project.
Data Unification Is Not What You’ve Been Doing
The data warehouse solved a storage and access problem. It put structured data in one place, made it queryable, and enabled reporting at scale. That was progress. It did not produce learning.
The data lake tried to solve the insight problem by storing everything. The bet was that having more data would produce better answers. What it produced was larger, harder-to-deprecate systems with quality and governance problems that weren’t visible at build time. The term “data swamp” exists for a reason.
The new data unification layer is different in kind. Signals flow in continuously — transactions, external market data, competitive intelligence, economic indicators. Context is preserved at the event level, not just the aggregate. Outcomes feed back into the system that generated the recommendation. The architecture is circular, not linear. Data doesn’t arrive, get processed, and sit. It arrives, gets interpreted, informs a decision, and the result of that decision comes back.
Most current implementations are not built this way. They’re sophisticated pipelines feeding static dashboards. The data moves. The learning doesn’t.
The First Mile Was Never a Technology Problem
Data doesn’t arrive clean, consistent, or shared in meaning. It arrives fragmented, labeled differently across systems, and reflecting the particular logic of whoever built each source.
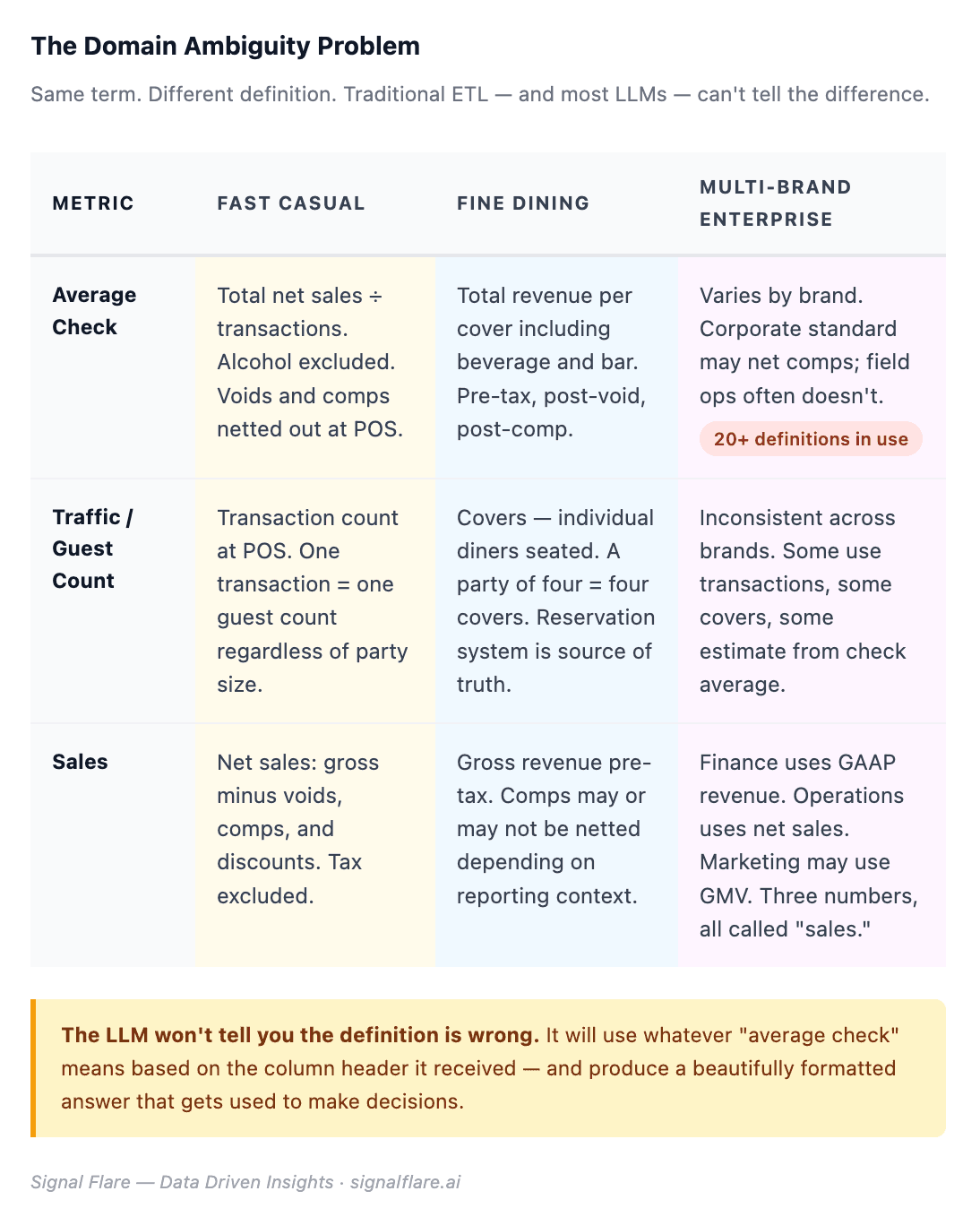
Traditional ETL couldn’t handle that variability. Every integration required a human domain expert at the point of ingestion, manually mapping terms and resolving conflicts. The first mile was expensive, slow, and dependent on institutional knowledge walking out the door whenever someone left.
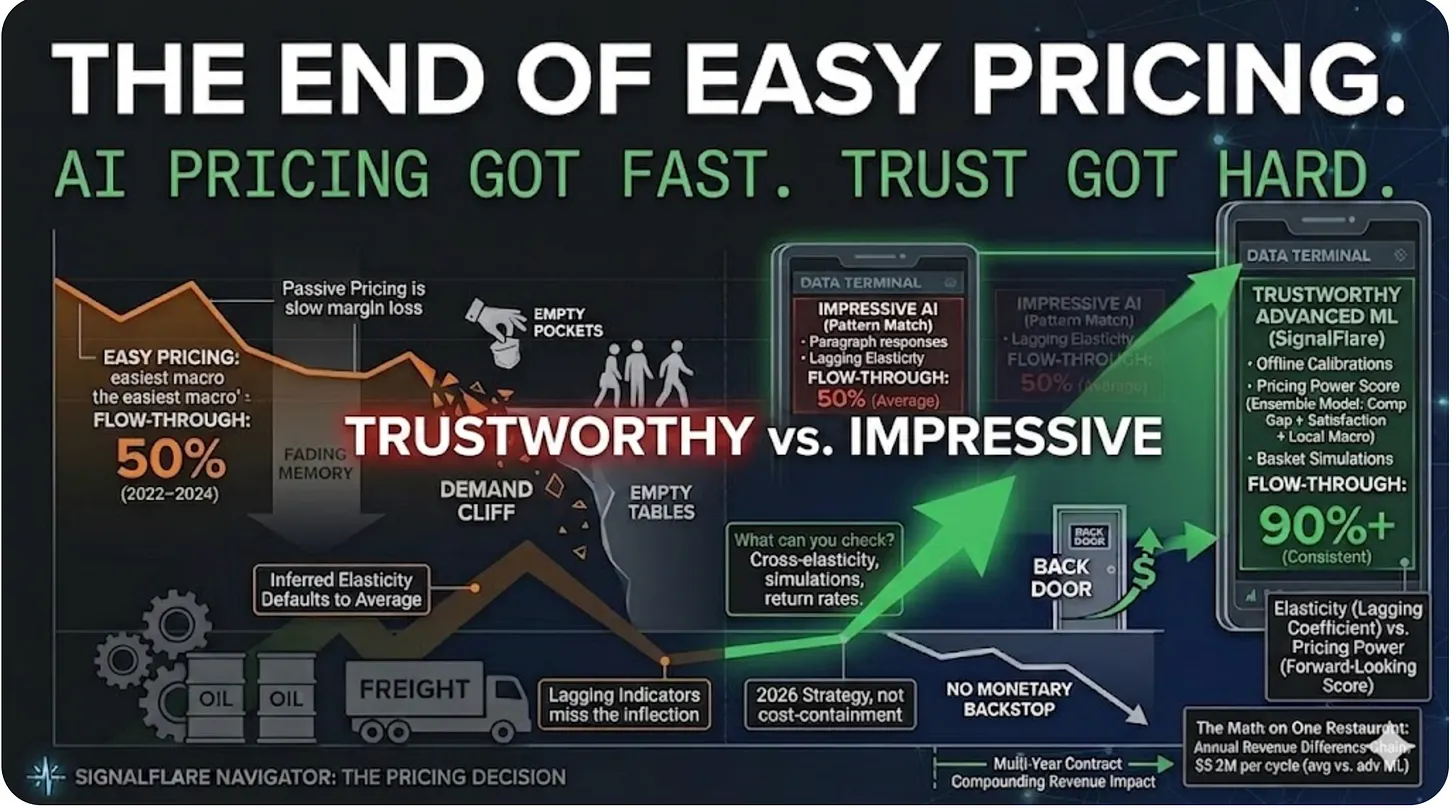
Here is the mistake being made right now, at scale, across almost every AI implementation in the industry: organizations are treating the Intelligence layer as if it solves the first mile. Feed the data to the LLM. Let the model figure it out. The output looks right — clean formatting, confident language, a number that answers the question. Nobody in the meeting pushes back.
The LLM won’t tell you the definition is wrong. It will produce a beautifully formatted answer. That answer will be used to make decisions. The error will surface months later, if it surfaces at all — buried in a variance that gets attributed to something else.
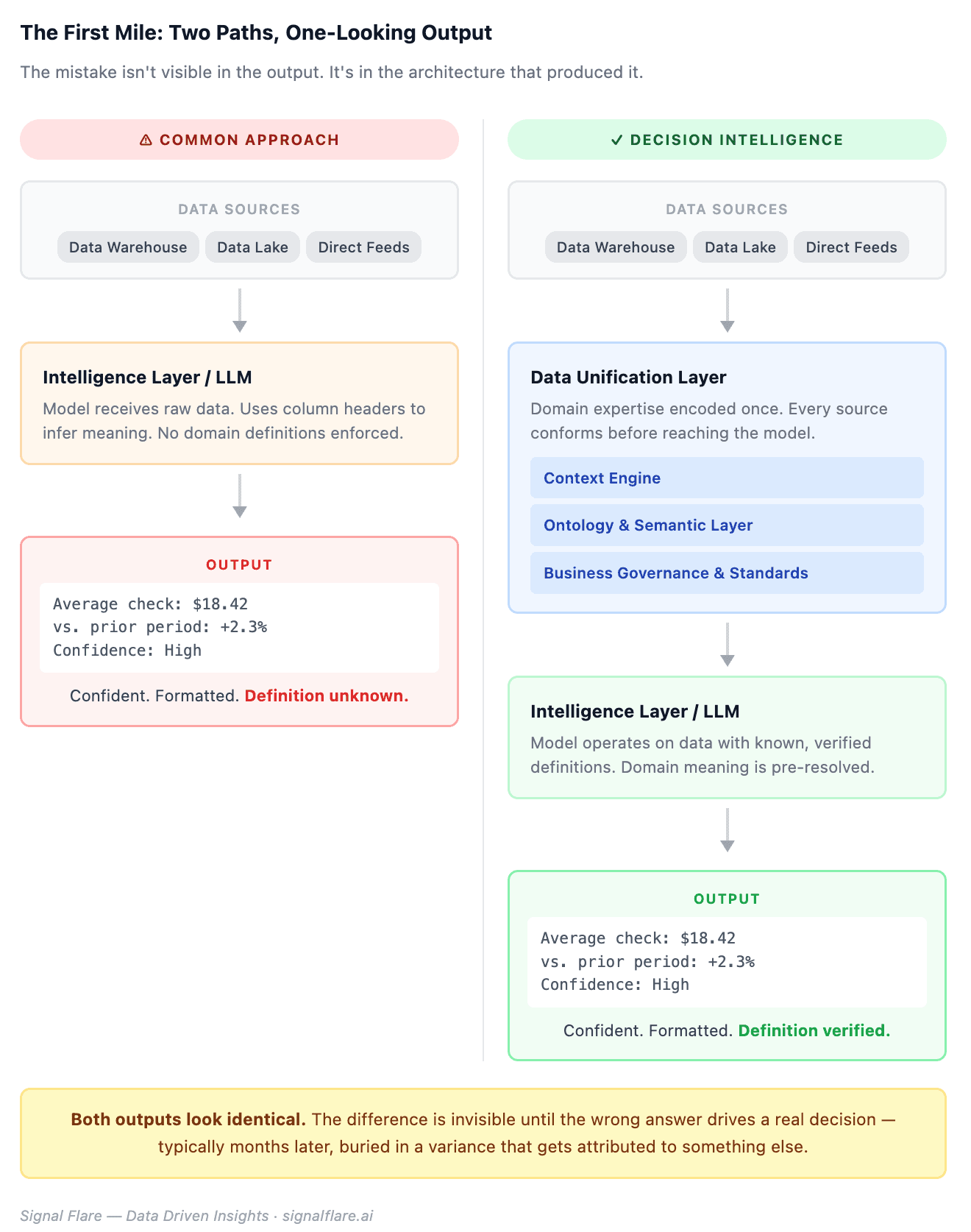
The Data Unification layer is not the Intelligence layer. It is the layer that makes the Intelligence layer trustworthy. It has its own components: a context engine that maps incoming data against established definitions, an ontology and semantic layer that holds the business’s specific meaning for every term, and a governance structure that enforces those standards before any data reaches the model. A traditional data warehouse or data lake can feed into this layer — but the unification work still has to happen. Skipping it doesn’t eliminate the first mile problem. It hides it.
Agents change what’s possible here not by being smarter than the problem, but by conforming to a semantic layer that already encodes the answer. The first mile becomes efficient not because the agent is clever. Because the foundation underneath it is sound.
The Last Mile Was the High-Value Problem Nobody Could Afford to Solve
The middle layer produced outputs. Those outputs went into dashboards. Humans read the dashboards, sometimes, on a delay, without enough context to act well. The last mile — context, meaning, “what should I do,” “what happens if I do A versus B,” recommendation to action to tracking — required bandwidth that most organizations didn’t have.
Take a menu change. It needs more than a sales trend. It needs attachment rate by daypart, check impact by segment, substitution patterns from prior tests, and a read on what’s shifted in the trade area since the last time something similar was tried. Building that picture manually, across teams, for every menu decision, every quarter, is not a reasonable ask. So it didn’t happen. Operators made menu decisions on intuition and comp store trends. Some of it worked. None of it accumulated.
Agents change the last mile not by making outputs better — though they can — but by closing the loop between recommendation and action, and between action and learning. The recommendation is grounded in your specific business context, not a generic model. The action is tracked. The outcome feeds back. The next similar decision starts from a better position than the last one did.
That is what the last mile was always supposed to be. The infrastructure to do it at scale didn’t exist until now.
The Project Thinking Trap
Here is the pattern that undermines most of this.
A company runs a price increase. They define a measurement window, build a dashboard, watch the comps for eight weeks, write up the results. The project closes. The learning lives in a slide deck.
Six months later, a different market runs a price increase. The analyst starts largely from scratch — pulling comparable periods, re-establishing baselines, re-arguing the methodology. There’s no system that says: here’s what happened the last four times you tested price in this segment, here’s the elasticity pattern, here’s what the two-store media test in Q3 told you about traffic sensitivity in this trade area.
The same thing happens with product launches, media tests, remodel programs, menu changes. Each one is treated as a discrete event to be measured and filed. Each one contains information that would improve the next decision. Almost none of that information transfers.
This is the project thinking trap. It is not an analytical failure. It is an architectural one.
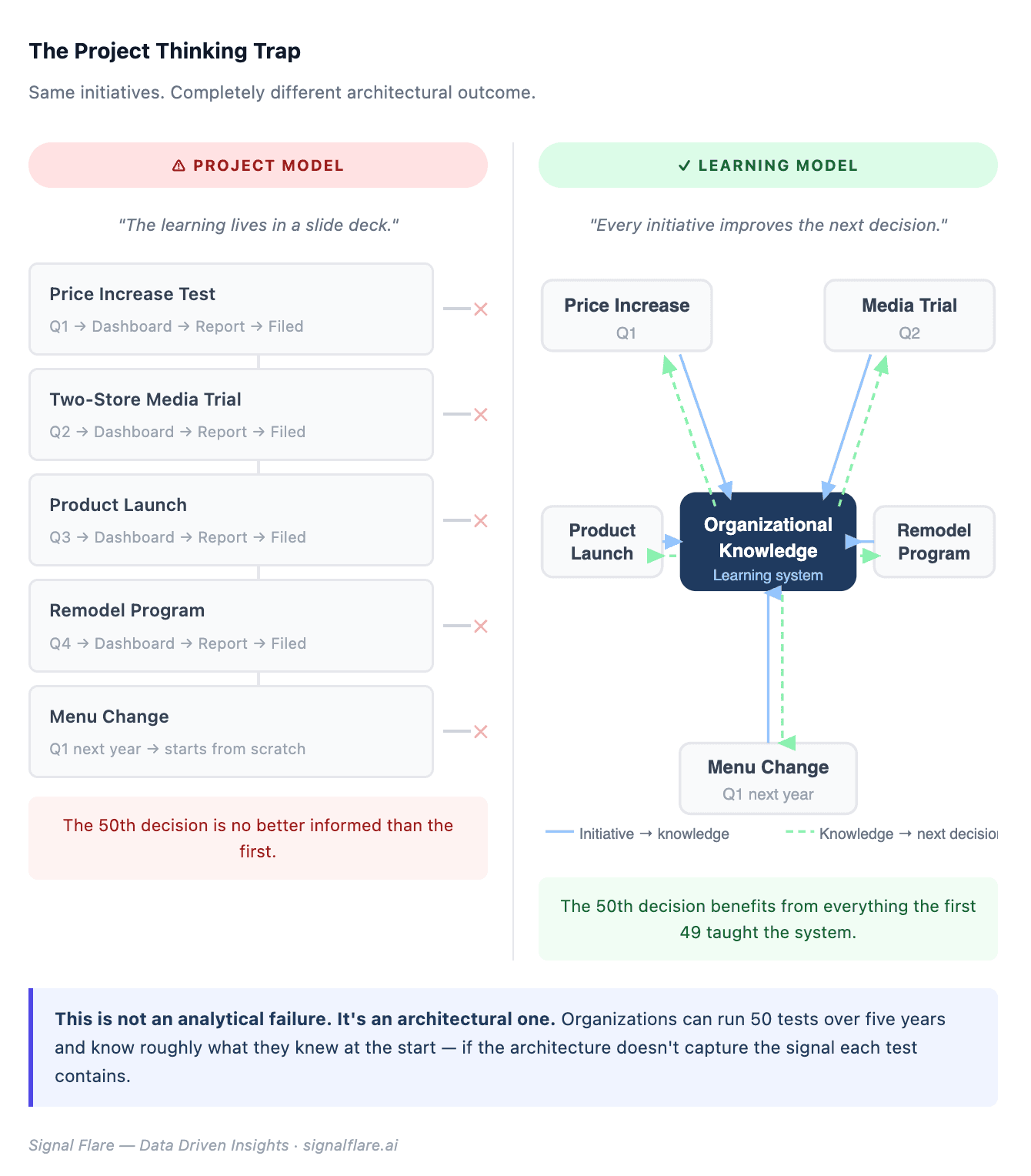
Every one of those initiatives is also a signal. It tells you something specific about how your customers behave, in which contexts, under which conditions. If your architecture treats each initiative as a closed event, you extract a fraction of the value it contained. The organization runs 50 tests over five years and knows roughly what it knew at the start. The 50th decision is not materially better than the first.
That is the outcome when organizations think in projects. It is also the default outcome when organizations buy AI tools for project-based use. A pricing analyst who queries Claude with a fresh data export every quarter is not building anything. They are querying. The difference between a tool and an asset is whether it accumulates.
Three Wrong Paths
There are three common approaches being deployed right now, each solving a real problem and each missing the larger one.
Chat wrappers on top of dashboards are stateless semantic queries. They answer the question you asked. They don’t learn from the answer. Every session starts from zero. The dashboard behind them is the same dashboard it was before the query. Nothing accumulates. This is better than staring at a spreadsheet. It is not Decision Intelligence.
LLMs ingesting raw data directly compound the domain accuracy problem described above — and add a security dimension. A model with broad access to your operational data is a model with broad access to your operational data. The prompt injection vulnerabilities documented in early 2026 are not edge cases. They are the predictable result of giving an LLM broad file access without a controlled semantic layer in between. The output looks confident. The exposure is real.
DIY agent stacks are controllable and sometimes excellent. Teams that understand what they’re building can produce novel, well-fit architectures. The problem is that enterprise-grade agentic AI — with proper sandboxing, governance, memory architecture, domain expertise, and the security posture that scales — is substantially harder to build and maintain than most teams account for. The Aalto University research published in 2025 found that the most AI-literate users were the most overconfident evaluators of AI outputs. The same pattern applies to the teams building AI infrastructure. The people most confident in their DIY capability are frequently the furthest from understanding the failure modes they’re building toward.
The Asset You Actually Own
The models are commoditizing. This is already visible in the market and will become more visible. The competitive advantage was never in which LLM you used. It was in what you built on top of it — and what you own independent of any single model provider.
Hierarchical memory, calibrated to your organization’s domain and decision context, is an asset. An ontology and semantic layer that encodes how your business actually works — not how a generic model thinks businesses work — is an asset. A learning loop that captures outcomes and improves the next decision is an asset. These things compound. They get more valuable with use. They cannot be replicated quickly by a competitor who starts later.
Stateless queries don’t compound. A fresh data export to a new session every quarter doesn’t compound. These are expenses, not investments. They solve the problem in front of you and leave the next problem exactly as hard as this one was.
The founding architecture of Decision Intelligence — Unification, Intelligence, Implementation — was always correct. The first mile and last mile are no longer the bottleneck. What’s left is whether your organization is building a learning system or running a series of projects.
Every Decision Is a Signal — If You Build a System That Captures It
Agentic AI made the first and last miles of Decision Intelligence executable at scale. That’s a meaningful shift. But the organizations that capture the value aren’t the ones deploying the most agents. They’re the ones with a semantic layer that grounds every agent in their specific domain, a memory architecture that accumulates learning across decisions rather than resetting after each project, and a governance posture that closes the loop between recommendation and outcome.
Every decision your business makes is a signal. The question is whether you’re building a system that captures it — or running another project that closes with a slide deck.
Data sources: Aalto University AI self-assessment study (2025); Anthropic system documentation on Claude Code sandboxing; PromptArmor prompt injection disclosure (January 2026); SignalFlare Navigator platform documentation.
Share